'data.frame': 944 obs. of 10 variables:
$ popul : int 0 190 31 83 640 110 100 31 180 2800 ...
$ TVnews: int 7 1 7 4 7 3 7 1 7 0 ...
$ selfLR: Ord.factor w/ 7 levels "extLib"<"Lib"<..: 7 3 2 3 5 3 5 5 4 3 ...
$ ClinLR: Ord.factor w/ 7 levels "extLib"<"Lib"<..: 1 3 2 4 6 4 6 4 6 3 ...
$ DoleLR: Ord.factor w/ 7 levels "extLib"<"Lib"<..: 6 5 6 5 4 6 4 5 3 7 ...
$ PID : Ord.factor w/ 7 levels "strDem"<"weakDem"<..: 7 2 2 2 1 2 2 5 4 1 ...
$ age : int 36 20 24 28 68 21 77 21 31 39 ...
$ educ : Ord.factor w/ 7 levels "MS"<"HSdrop"<..: 3 4 6 6 6 4 4 4 4 3 ...
$ income: Ord.factor w/ 24 levels "$3Kminus"<"$3K-$5K"<..: 1 1 1 1 1 1 1 1 1 1 ...
$ vote : Factor w/ 2 levels "Clinton","Dole": 2 1 1 1 1 1 1 1 1 1 ...Regression for Multinomial and Ordinal Outcomes
1996 National Election Study
1996 National Election Study
Let’s continue with some visual exploration:
Show R code
library(dplyr)
library(ggplot2)
theme_set(theme_bw())
# Aggregate data; what's happening here?
egp <- group_by(rnes96, education, party) %>%
summarise(count = n()) %>%
group_by(education) %>%
mutate(etotal = sum(count), proportion = count/etotal)
# Plot results
ggplot(egp, aes(x = education, y = proportion, group = party,
linetype = party, color = party)) +
geom_line(size = 2)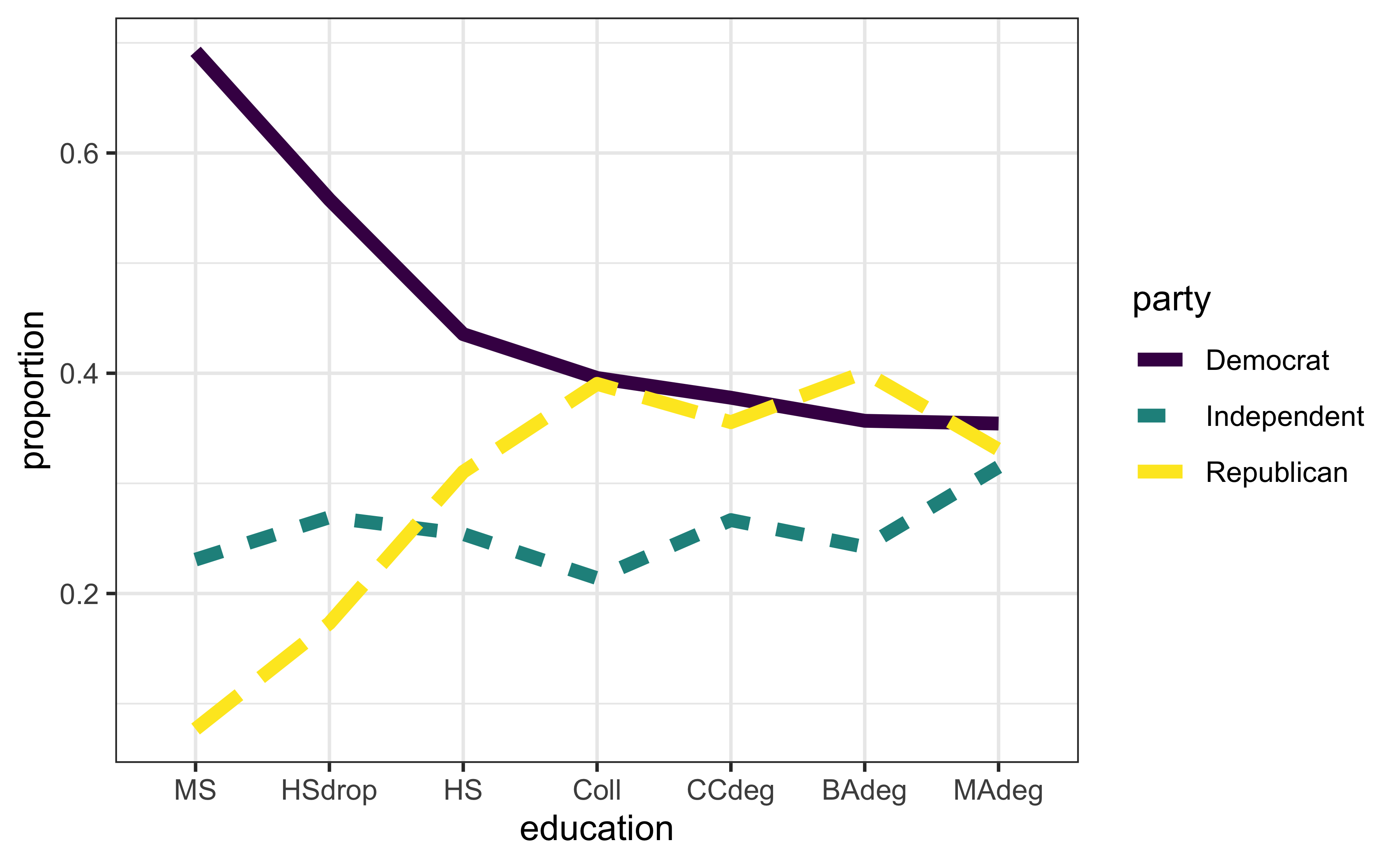
1996 National Election Study
Let’s continue with some visual exploration:
Show R code
# Aggregate data; what's happening here?
igp <- mutate(rnes96, income_group = cut_number(income, 7)) %>%
group_by(income_group, party) %>%
summarise(count = n()) %>%
group_by(income_group) %>%
mutate(etotal = sum(count), proportion = count / etotal)
# Plot results
ggplot(igp, aes(x = income_group, y = proportion, group = party,
linetype = party, color = party)) +
scale_x_discrete(guide = guide_axis(angle = 45)) +
geom_line(size = 2)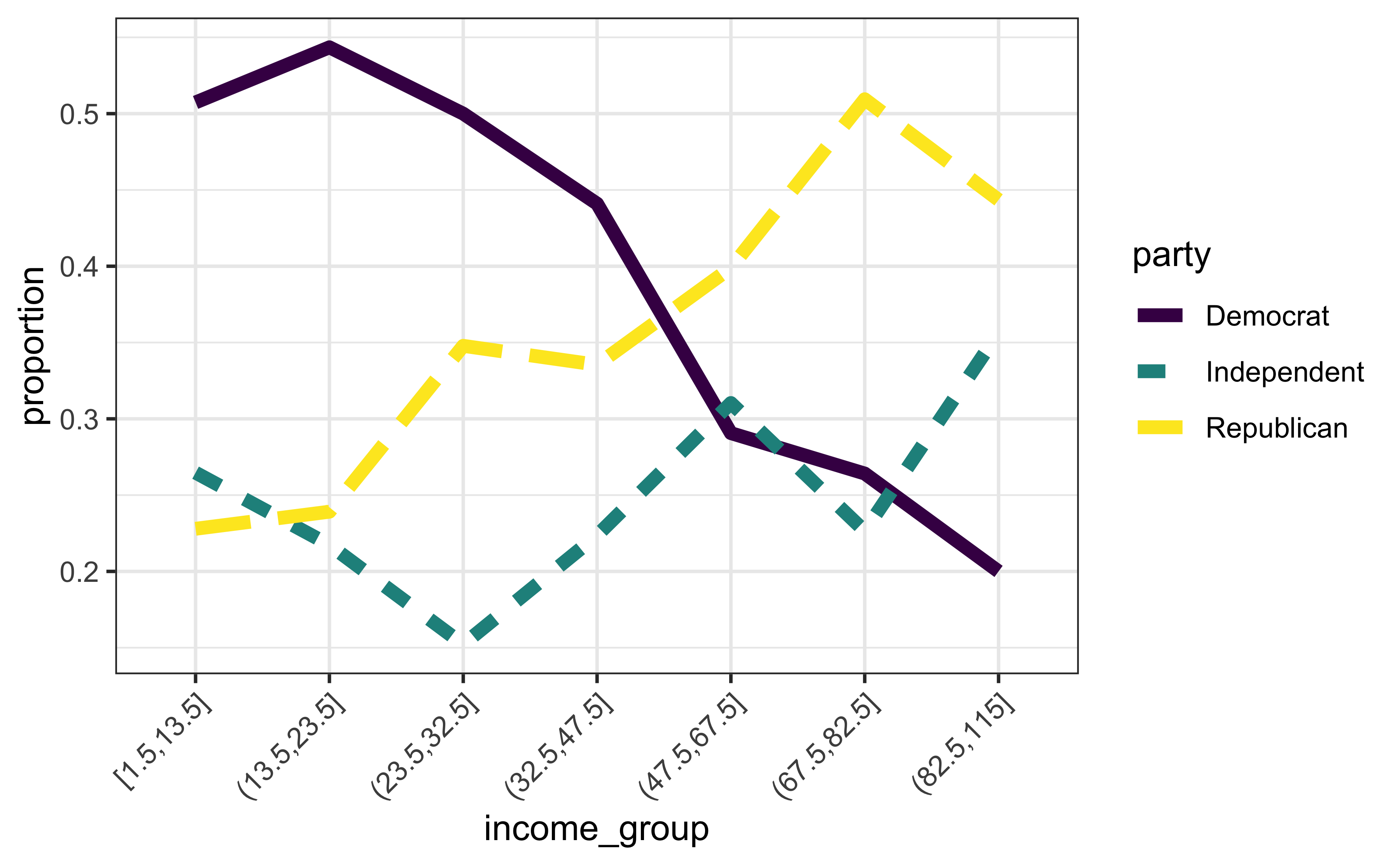
1996 National Election Study
Let’s continue with some visual exploration:
Show R code
# Aggregate data; what's happening here?
agp <- rnes96 %>%
group_by(age, party) %>%
summarise(count = n()) %>%
group_by(age) %>%
mutate(etotal = sum(count), proportion = count / etotal)
# Plot results
ggplot(agp, aes(x = age, y = proportion, group = party,
linetype = party, color = party)) +
geom_line(size = 1, alpha = 0.5)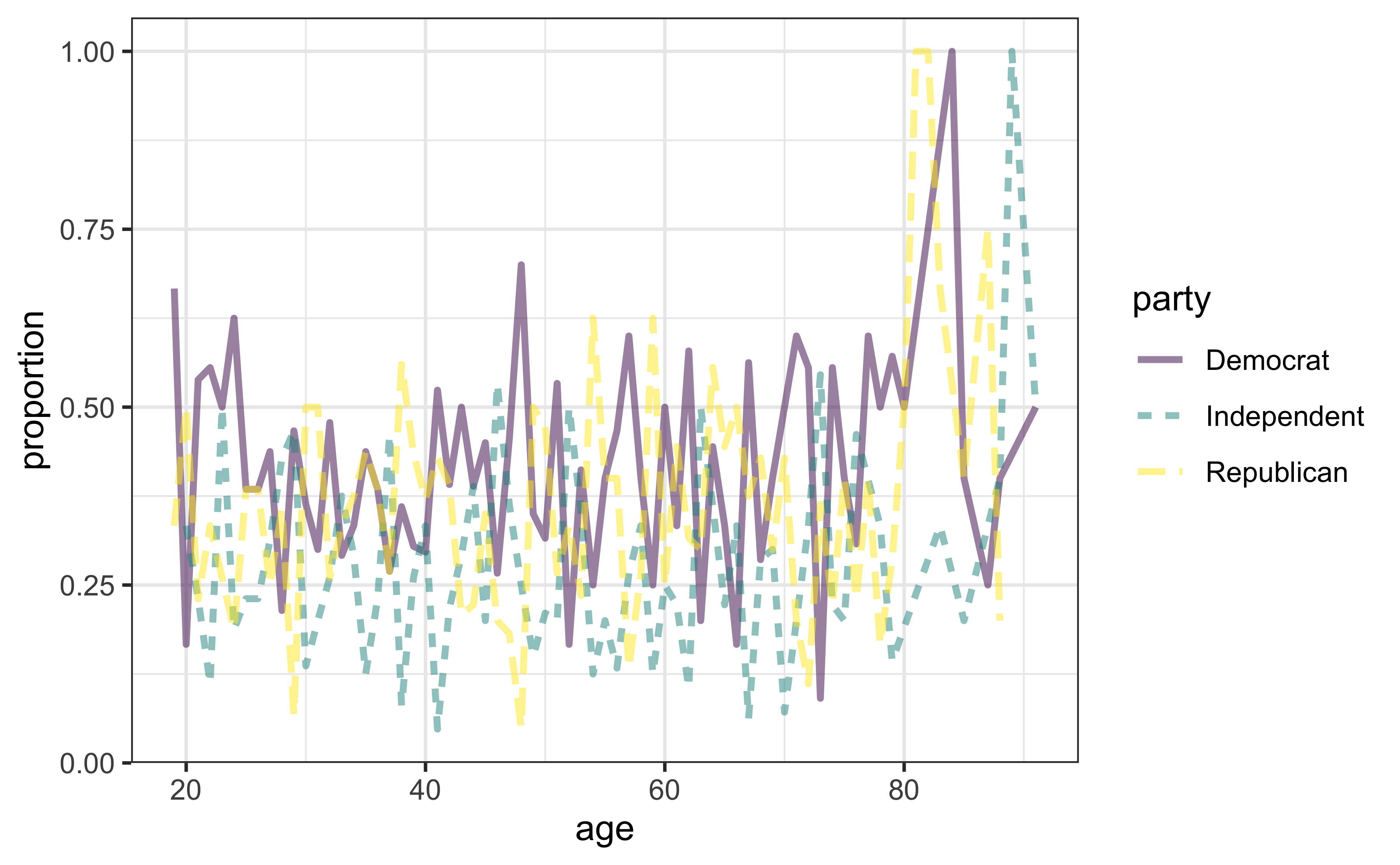
Brief digression…
By default, R encodes ordered factors using orthogonal polynomials
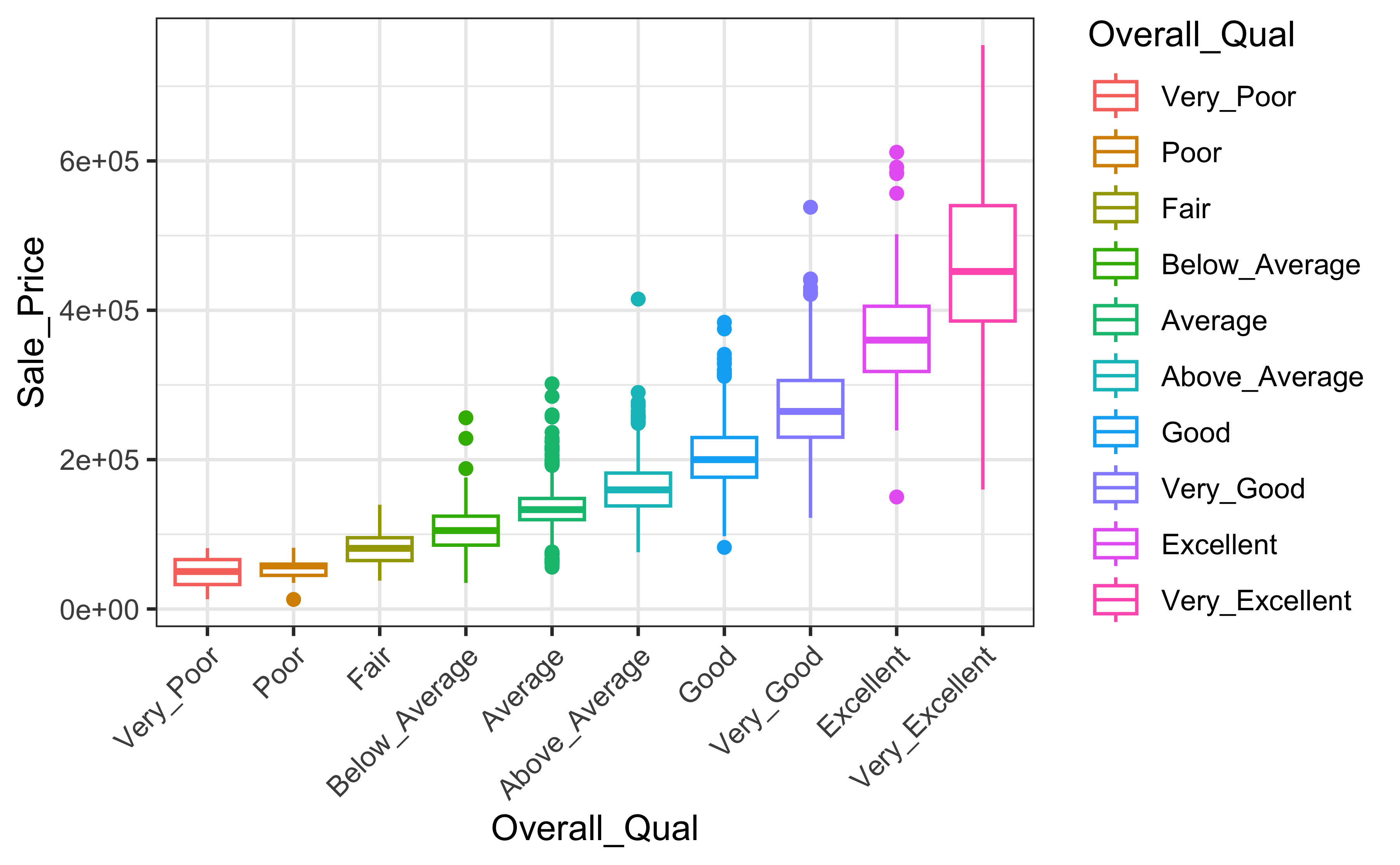
Ames Housing example:
1996 National Election Study
Show R code
library(pdp) # for partial dependence (PD) plots
# Compute partial dependence of party identification on income
pfun <- function(object, newdata) {
probs <- predict(object, newdata = newdata, type = "probs")
colMeans(probs) # return average probability for each class
}
pd.inc <- partial(mfit, pred.var = "income", pred.fun = pfun)
ggplot(pd.inc, aes(x = income, y = yhat, linetype = yhat.id, color = yhat.id)) +
geom_line(size = 2) +
xlab("Income group midpoint (in thousands)") +
ylab("Partial dependence")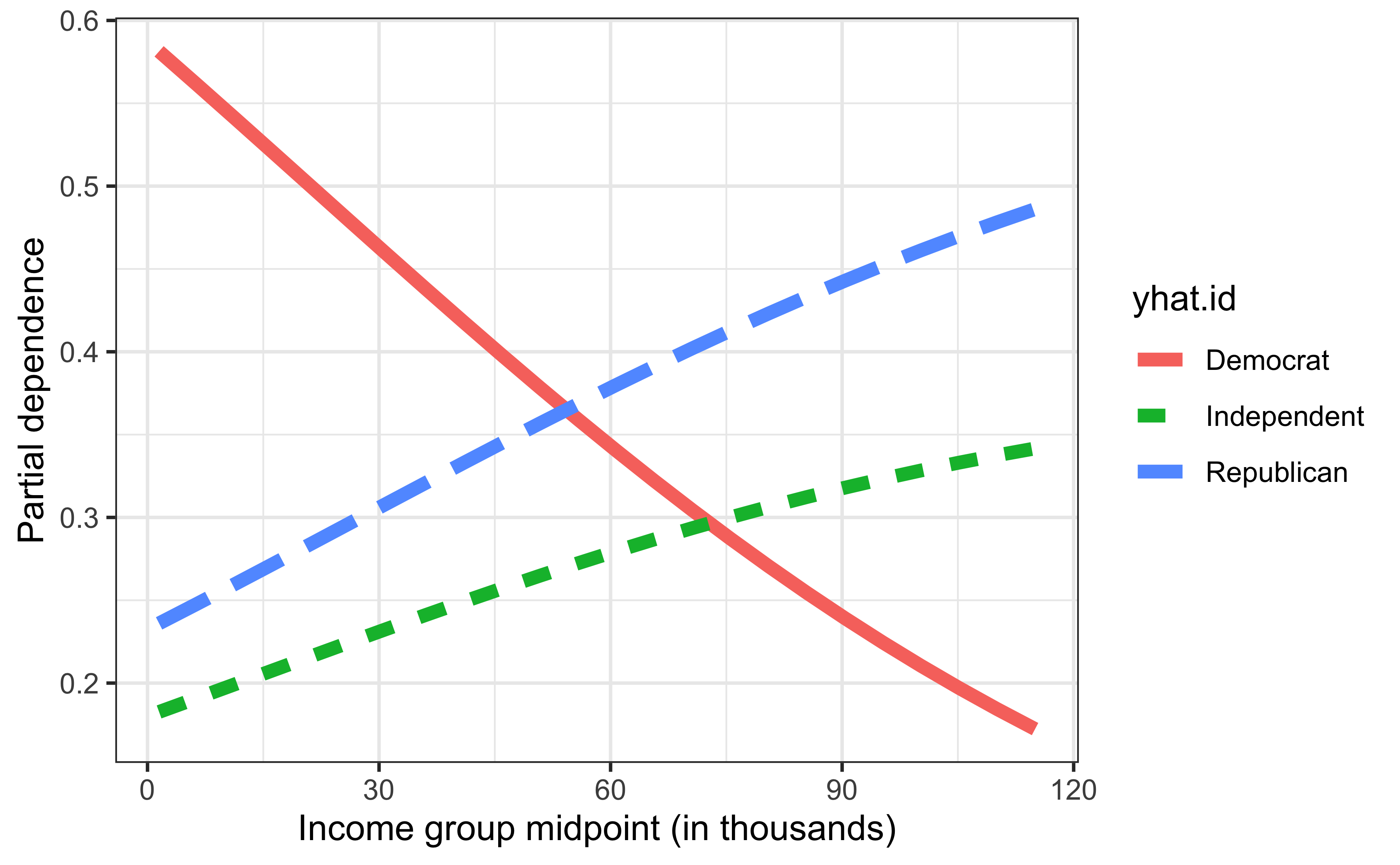
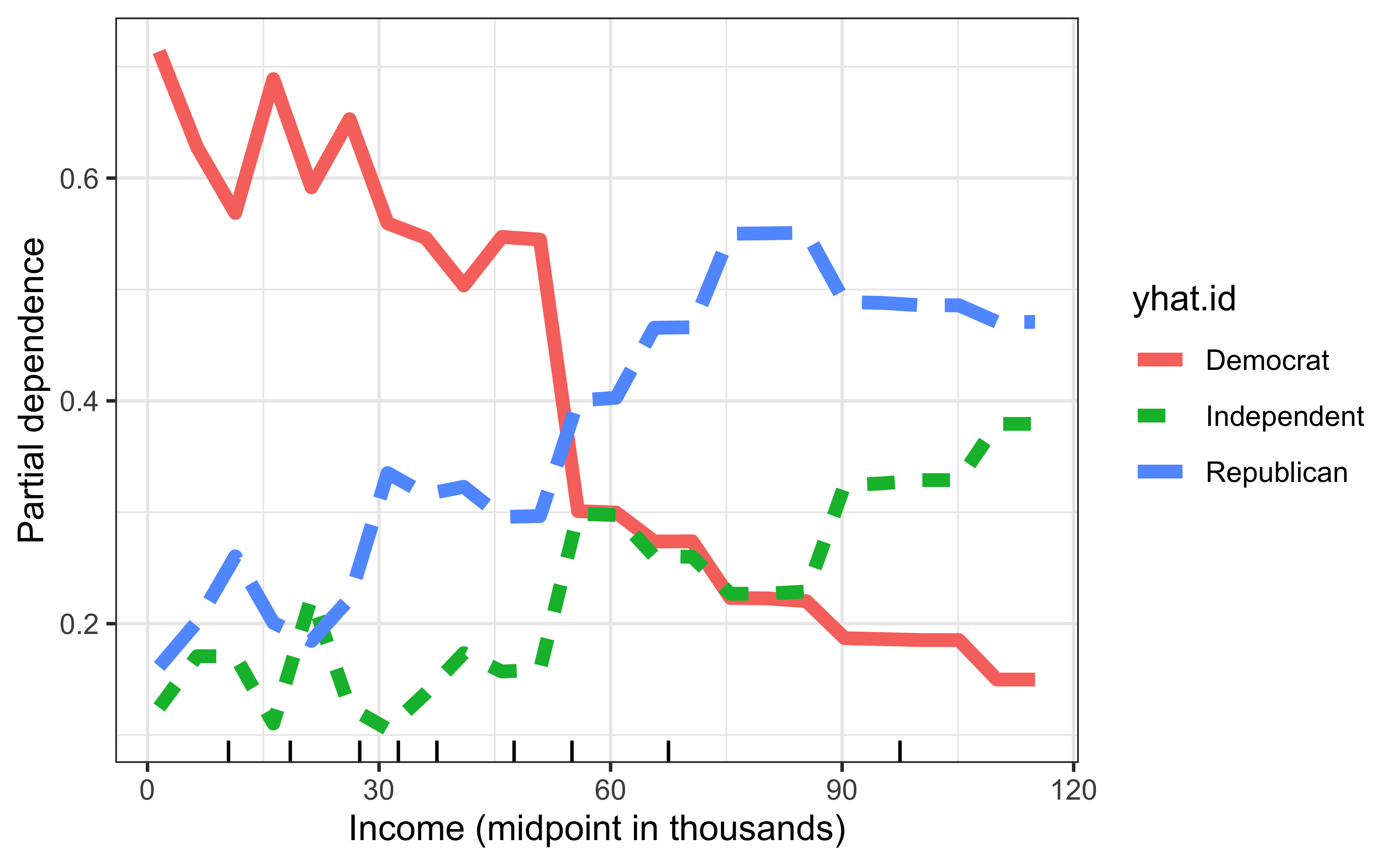
1996 National Election Study
Random forest results for comparison:
Show R code
# Construct the same PD plot as before, but using the RF model
pd <- partial(rfo, pred.var = "income", pred.fun = function(object, newdata) {
colMeans(predict(object, newdata = newdata, type = "prob"))
})
ggplot(pd, aes(x = income, y = yhat, linetype = yhat.id, color = yhat.id)) +
geom_line(size = 2) +
xlab("Income (midpoint in thousands)") +
ylab("Partial dependence") +
geom_rug(data = data.frame("income" = quantile(rnes96$income, prob = 1:9/10)), aes(x = income), inherit.aes = FALSE)